我们专注于使用人工智能技术对文本、影像数据的处理与理解,为用户提升其生产力和决策能力。
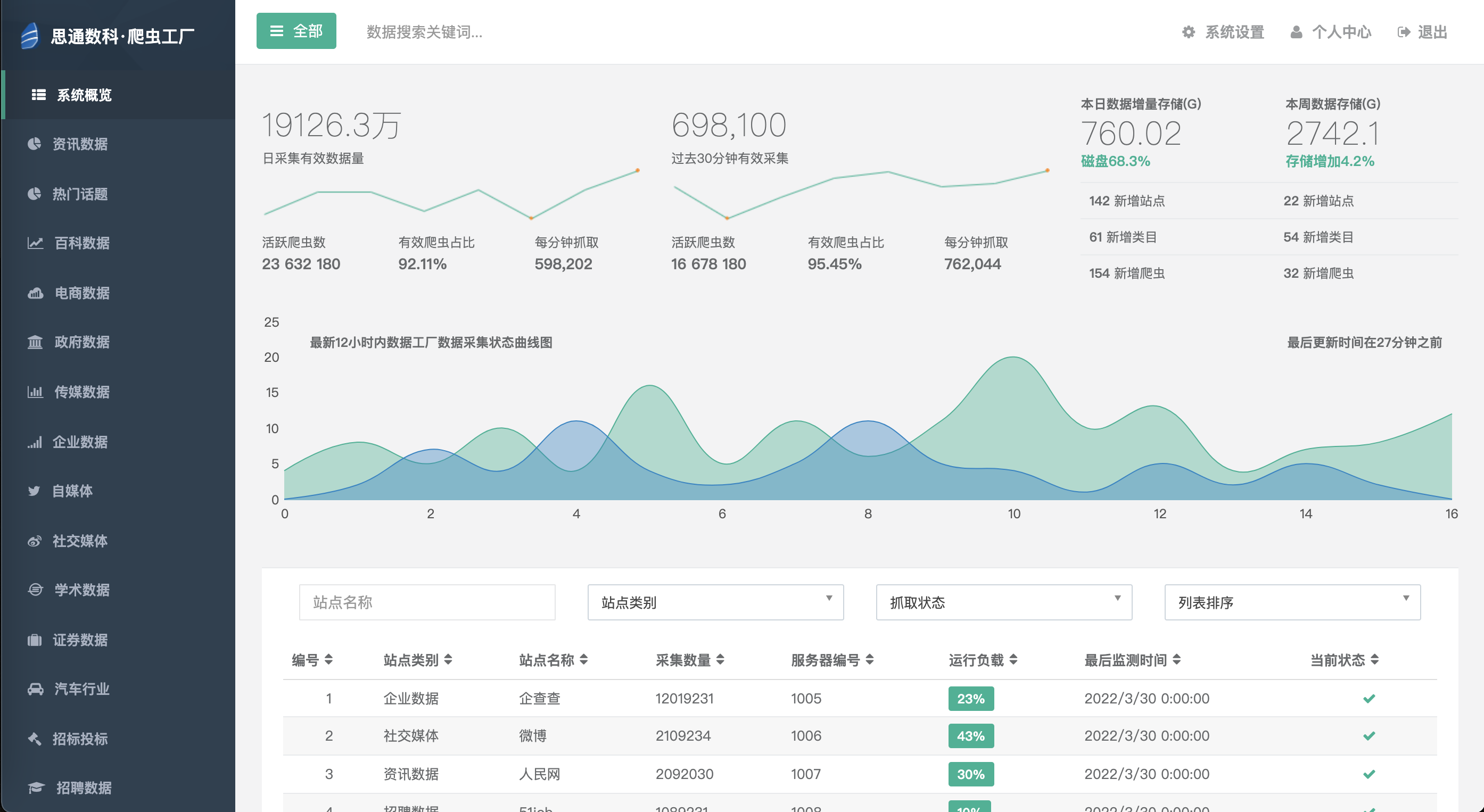
在我们推出开源的 思通舆情系统后,在开源社区受到了广大用户的喜爱和关注,很多用户对我们的数据采集技术、后端海量数据运算非常感兴趣。 思通舆情 在线生产环境 使用了24个节点的 Elasticsearch集群存储,每天在互联网上采集的2亿多条 ......
互联网数据采集的应用场景非常广泛,一般用于 情报收集、舆情分析、竞争对手分析、学术研究、市场分析、用户口碑监测 ,在数据采集的过程中大多数网站都是以标题,时间,摘要,作者,来源,正文等形式展现,但是会遇到千千万万种不同结构的网页,开发者不可 ......
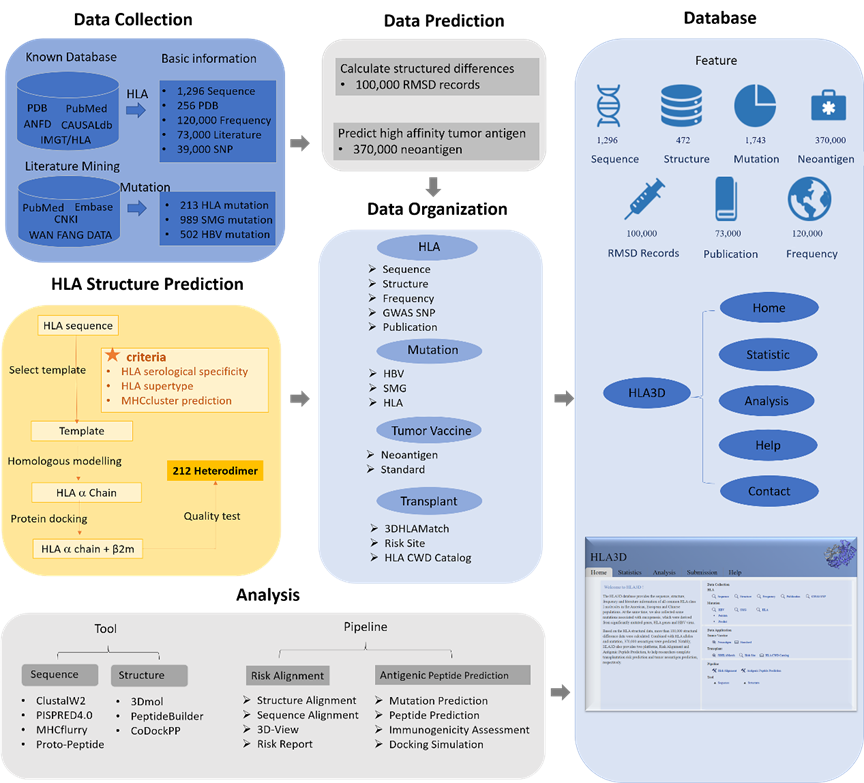
近日,南京基因与细胞实验室合作团队取得阶段性成果,东南大学-生命科学与技术学院-李健教授团队在《Briefings in Bioinformatics》(影响因子IF=11.622)上发表题“HLA3D: an integrated str ......
Cassandra是一套开源分布式NoSQL数据库系统。它最初由Facebook开发,用于储存收件箱等简单格式数据,此后,由于Cassandra良好的可扩展性,被Digg、Twitter等知名Web 2.0网站所采纳,成为了一种流行的分布式 ......
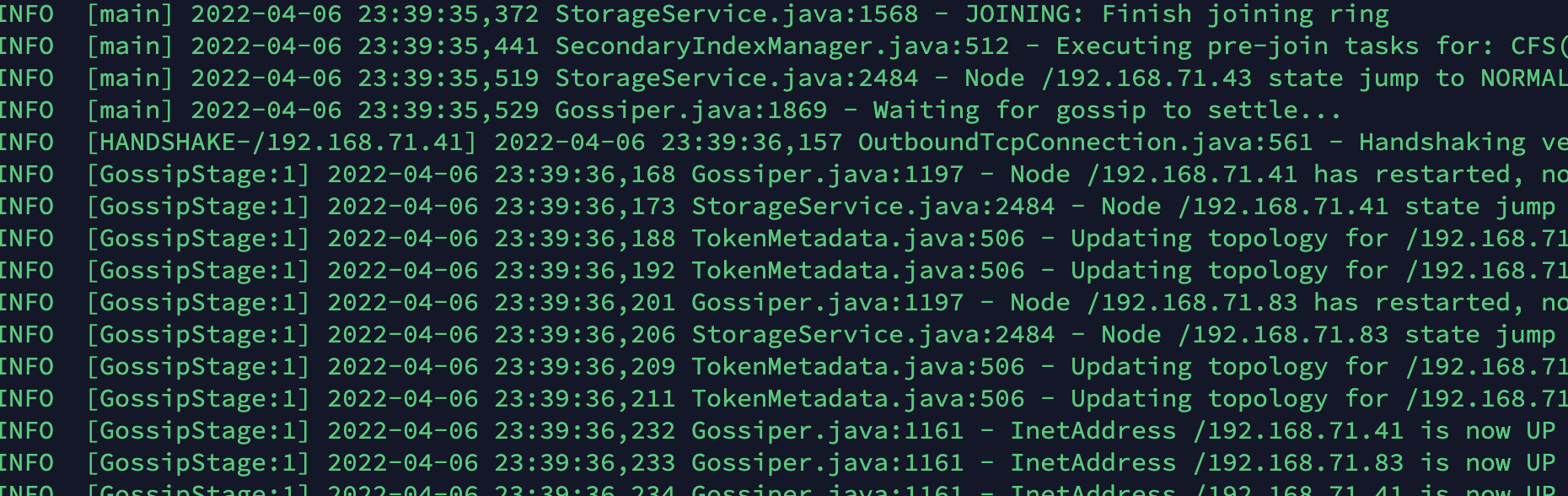
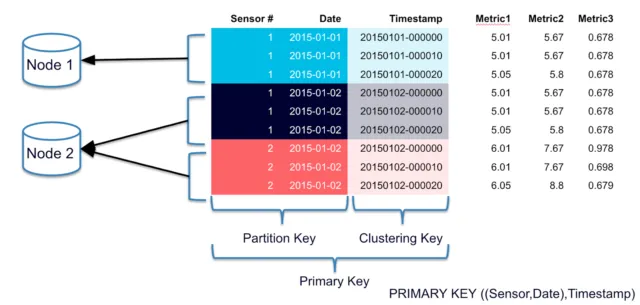
执行 select count(*) from mytable 只能在小数据量的时候对 Cassandra 进行count查询检索, 但遇到大数据量的时就会报下面的错误信息: ReadTimeout: Error from server: ......
国内大多数公司和开发者对Mongodb和Hbase推崇备至,这是因为MongoDB进入了国内市场并建立了中文社区,而Hbase在阿里的大范围使用和推广下培养了一大批用户和公开材料。Cassandra最近两年在大数据公司Datastax的大力 ......
在大数据时代,数据采集或网络爬虫似乎是每个程序员的必备技能,一般情况下,工程师会通过Python爬虫框架快速的编写出爬虫程序对网页数据抓取,不过在大规模数据采集的时候就不是一个简简单单的爬虫程序了。例如,分布式爬虫系统,在为我们的舆情系统( ......
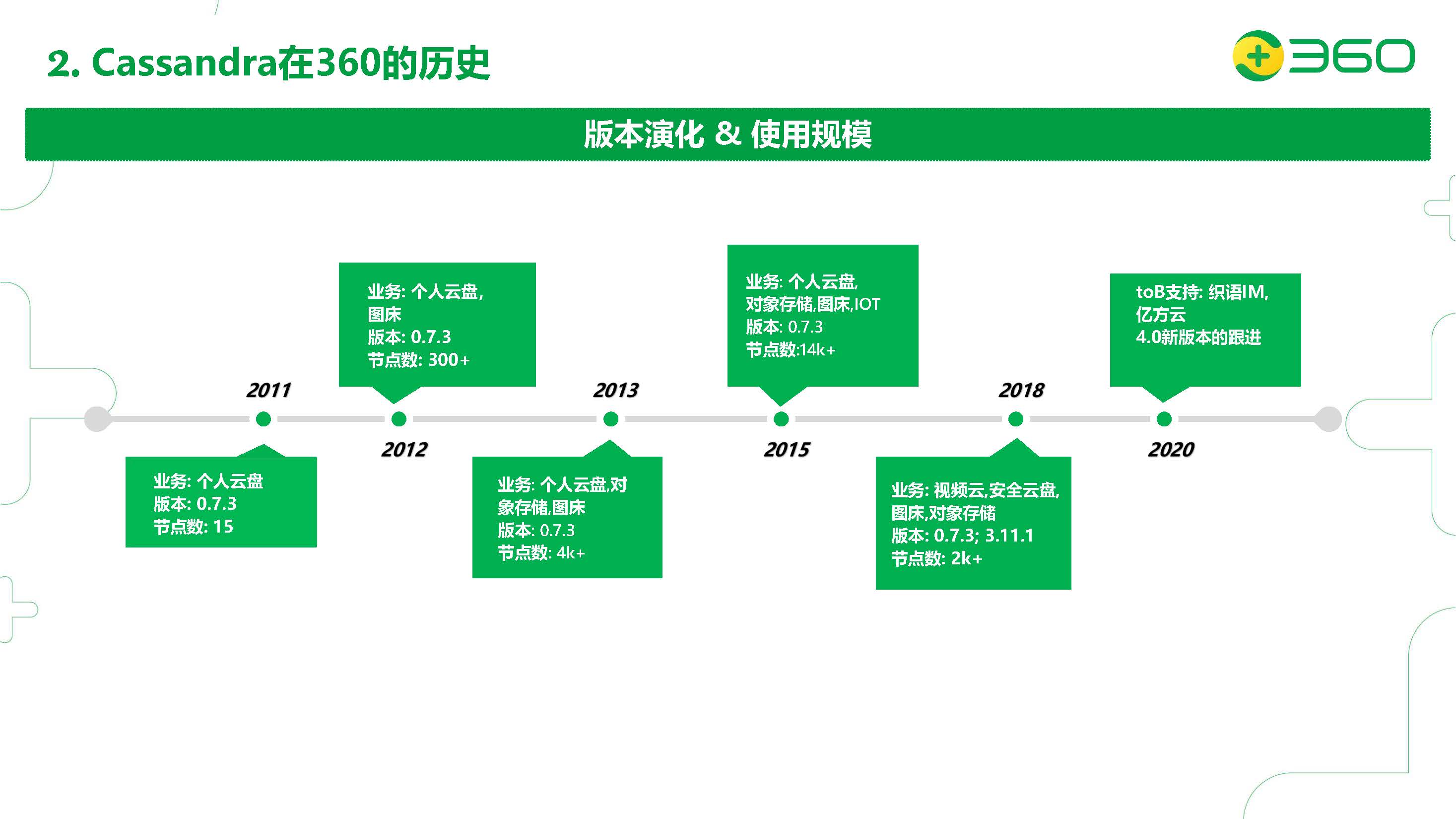
网上能找到被披露的信息中奇虎360公司是国内目前 Cassandra 落地规模最大的公司。 Cassandra 自2010在360开始调研技术落地;2011年使用 Cassandra 0.7.3作为基础版本应用于生产环境;2012年完善数据 ......
Cassandra起源 2007 年 Facebook 为了解决消息收件箱搜索问题( Inbox Search problem)而开始设计 Cassandra 项目。 当时 Facebook 遇到了传统的方法难以解决的超大数据量存储可扩展性 ......
一、背景描述 目前后端数据引擎系统中 使用了24个节点的 Elasticsearch 集群,存储每天采集1.7亿条上下的数据量,具体的网页原始数据存储在 Cassandra 集群中。一个月下来抓取的数据量超过2T,同时要保证每天450台爬虫 ......